NSX-T Transitive Networking
One major advantage to NSX-T is that Edge Transport Nodes (ETNs) are transitive
Transitivity (Wikipedia) (Consortium GARR) is an extremely important concept in network science, and in computer networking.
In simple terms, a network node (any speaker capable of transmitting or receiving on a network) can have the following transitivity patterns:
- Transitive: Most network equipment fit in this category. The primary purpose of these devices is to allow traffic to flow through them and to occasionally offer services over-the-top.
- Examples:
- Switches
- Routers
- Firewalls
- Load Balancers
- Service Meshes
- Any Linux host with
ip_forwardset - Mobile devices with tethering
- Examples:
- Non-Transitive: Most servers, client devices fit in this category. These nodes are typically either offering services over a network or consuming them (Usually both). In nearly all cases, this is a deliberate choice by the system designer for loop prevention purposes.
- Note: It's completely possible to participate in a routing protocol while being non-transitive.
- Examples:
- VMware vSphere Standard Switch && vSphere Distributed Switch (no Spanning-Tree participation)
- Amazon vPC
- Azure VNet
- Any Linux host with ip_forward disabled
- Nearly any server, workstation, mobile device
- Anti-Transitive: This is a bit of a special use case, where traffic is transitive but only in specific use cases. Anti-Transitive network nodes have some form of control in place to prevent transit in specific scenarios but allowing it in others. The most common scenario is when an enterprise has multiple service providers - where the enterprise doesn't want to pay for traffic going between those two carriers.
- Examples:
- Amazon Transit Gateway
- Any BGP Router with import/export filters
- Examples:
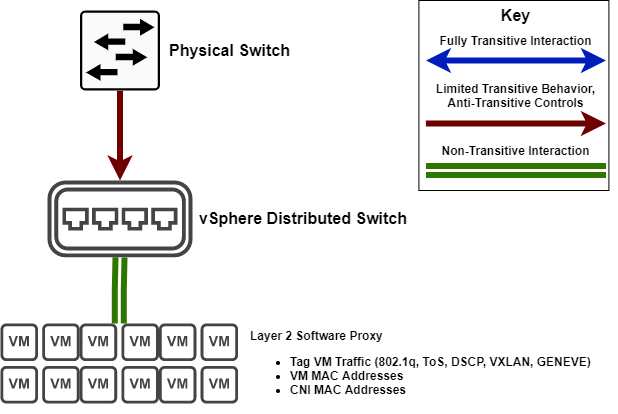
vSphere Switch Transitive Networking Design
To fully understand VMware's approach, it is important to first understand earlier approaches to network virtualization. vSphere switches are a bit of a misnomer, as you don't actually switch at any given point. Instead, vSphere switches leverage a "Layer 2 Proxy" of sorts, where NIC-accelerated software replaces ASIC flow-based transitive switching.
This approach offers incredible flexibility, but is theoretically slower than software switching; to preserve this capability VMware noticed early on that loop prevention would become an issue. Pre-empting this problem, making the platform completely non-transitive to ensure that this flexibility will be more readily adopted.
Note: VMware's design choices here contained the direct intent to simplify the execution and management of virtualized networking. This choice made computer networking simple enough for most typical VI administrators to perform, but more of the advanced features (QoS, teaming configurations) require more direct involvement from network engineers to execute well. Generally speaking, the lack of need for direct networking intervention for a VSS/vDS to work has led to a negative trend with the VI administrator community. Co-operation between VI administration and networking teams often suffer due to this lack of synchronization, and with it systems performance as well.
NSX-T Transitive Networking Design
NSX-T is highly prescriptive in terms of topology. VMware has known for years that a highly controlled design for transitive networking will provide stability to the networks it may participate in - just look at the maturity/popularity of vDS vs Nexus 1000v.
NSX-T does depend on VDS for Layer 2 forwarding (as we've established, not really switching), but does follow the same general principles for design.
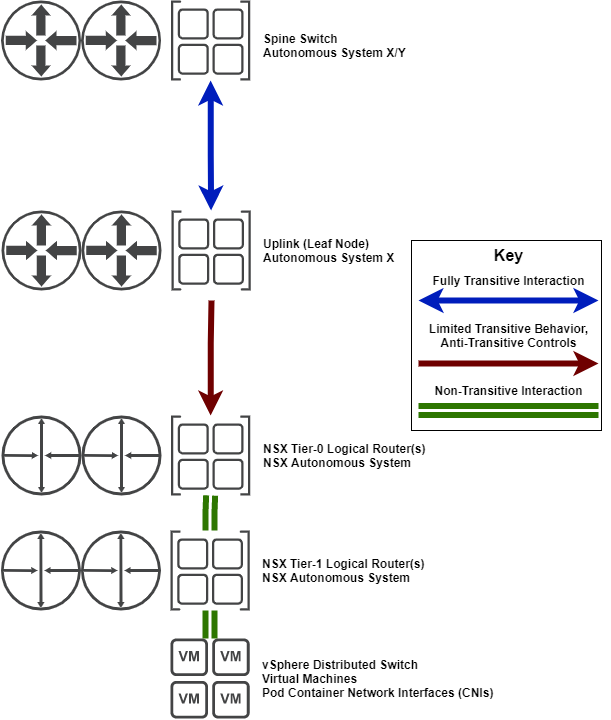
To be stable, you have to sacrifice flexibility. This is for your own protection. These choices are artificial design limitations, intentionally placed for easy network virtualization deployment.
VMware NSX-T Tier-0 logical routers have to be transitive to perform their main goal, transporting overlay traffic to underlay network nodes. Every time a network node becomes transitive in this way, specific design decisions must be made to ensure that anti-transitive measures are appropriately used to achieve network stability.
NSX-T Tier-1 Distributed routers are completely nontransitive, and NSX-T Tier-1 Service Routers have severely limited transitive capabilities. I have diagrammed this interaction as non-transitive because the Tier-1 services provided are technically owned by that logical router.
Applications for Transitive Tier-0 Routers
Given how tightly controlled transit is with NSX-T, the only place we can perform these tasks is via the Tier-0 Logical Router. Let's see if it'll let us transit networks originated from a foreign device, shall we?
Hypothesis
NSX-T Tier-0 Logical Routers are capable as transit providers, and the only constructs preventing transit are open standards (BGP import/export filters)
Unit Test
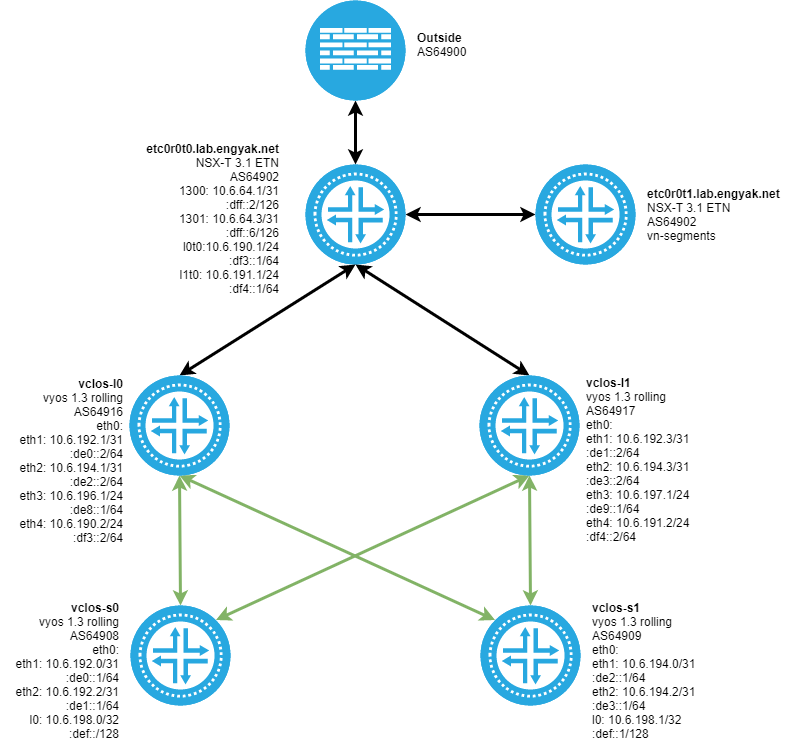
Peer with vCLOS network via (transiting) NSX-T Tier-0 Logical Router:
Let's build it, starting with the vn-segments:
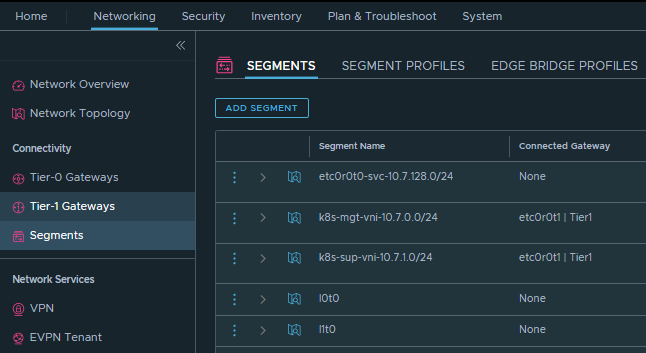
Then, configuring Tier-0 External Interfaces:
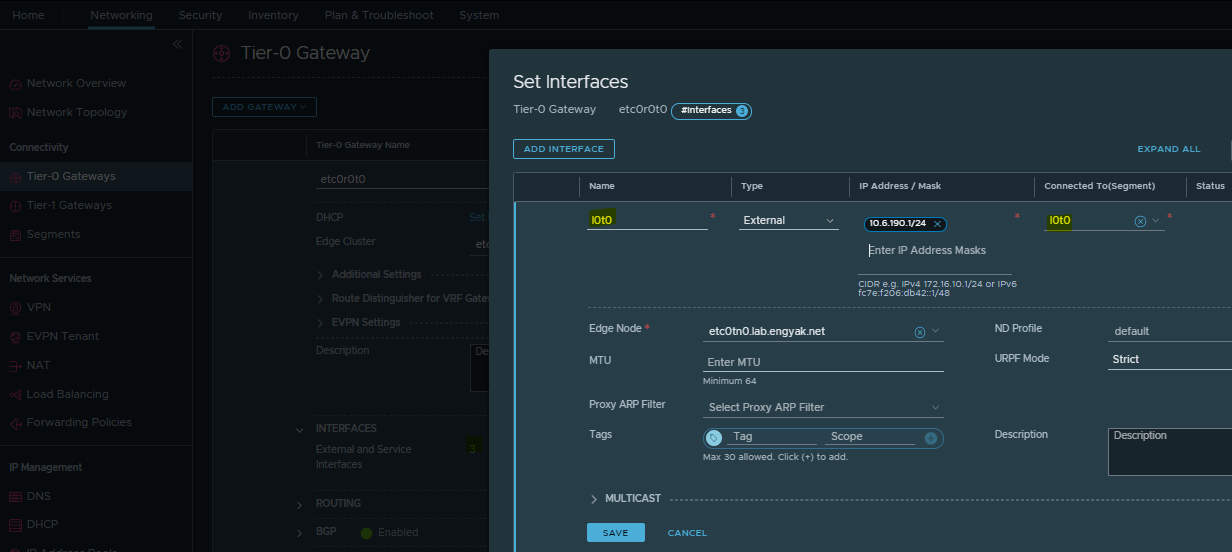
Ensure that we're re-distributing External Interface Subnets:
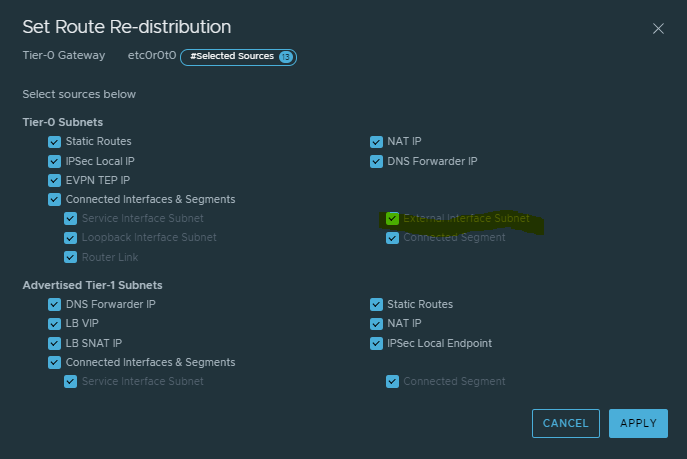
Ensure that the additional prefixes are being advertised. Note: This is a pretty big gripe of mine with the NSX GUI - we really ought to be able to drill down further here...
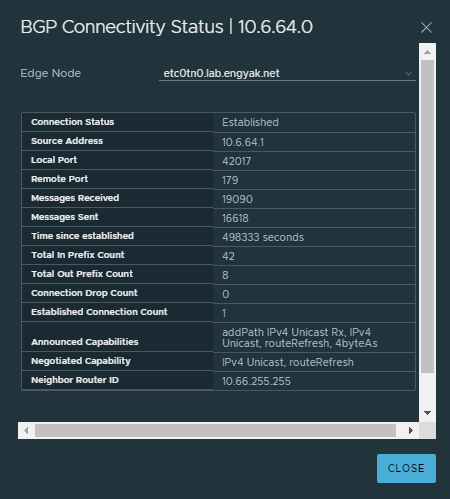
Configure BGP Peering to the VyOS vCLOS Network:
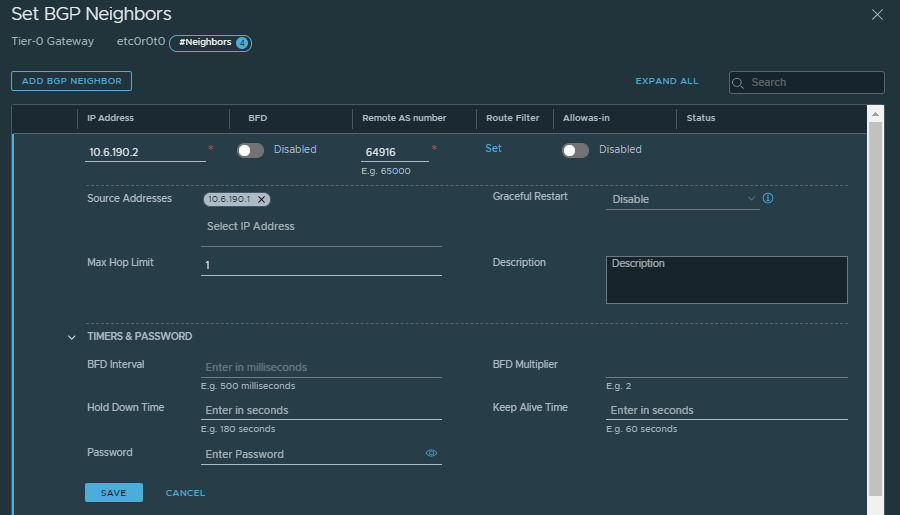
We're good to go on the NSX Side. In theory, this should provide a transitive peering, as BGP learned routes are not Re-Distributed but learned.
(The other side is VyOS, configured in the pipeline method outlined in a previous post. This pipeline delivery method is really growing on me)
We can verify that prefixes are propagating transitively via the NSX-T Tier-0 in both protocol stacks by checking in on the spines that previously had no default route:
1vyos@vyos-s1.engyak.net:~$ show ip route
2Codes: K - kernel route, C - connected, S - static, R - RIP,
3 O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
4 T - Table, v - VNC, V - VNC-Direct, A - Babel, D - SHARP,
5 F - PBR, f - OpenFabric,
6 > - selected route, * - FIB route, q - queued, r - rejected, b - backup
7
8B>* 0.0.0.0/0 [20/0] via 10.6.194.1, eth1, weight 1, 00:15:20
9B>* 10.0.0.0/8 [20/0] via 10.6.194.1, eth1, weight 1, 00:15:20
10vyos@vyos-s1.engyak.net:~$ show ipv6 route
11Codes: K - kernel route, C - connected, S - static, R - RIpng,
12 O - OSPFv3, I - IS-IS, B - BGP, N - NHRP, T - Table,
13 v - VNC, V - VNC-Direct, A - Babel, D - SHARP, F - PBR,
14 f - OpenFabric,
15 > - selected route, * - FIB route, q - queued, r - rejected, b - backup
16
17B>* ::/0 [20/0] via fe80::250:56ff:febc:b05, eth1, weight 1, 00:15:25
Now, to test whether or not packets actually forward:
1vyos@vyos-s0.engyak.net:~$ ping 1.1.1.1
2PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
364 bytes from 1.1.1.1: icmp_seq=1 ttl=53 time=49.7 ms
464 bytes from 1.1.1.1: icmp_seq=2 ttl=53 time=48.10 ms
564 bytes from 1.1.1.1: icmp_seq=3 ttl=53 time=45.9 ms
664 bytes from 1.1.1.1: icmp_seq=4 ttl=53 time=45.0 ms
Looks like Tier-0 Logical Routers are transitive! This can have a lot of future implications - because NSX-T can become a launchpad for all sorts of virtualized networking. Some easy examples:
- Tier-0 Aggregation: Like with aggregation-access topologies within the data center and campus, this is a way to manage BGP peer/linkage count at scale, allowing for thousands of Tier-0 Logical Routers per fabric switch.
- Load Balancers: This shifts the peering relationship for load balancers/ADC platforms from a direct physical peering downward, making those workloads portable (if virtualized)
- Firewalls: This provides Cloud Service Providers (CSP) the ability to provide customers a completely virtual, completely customer-owned private network, and the ability to share common services like internet connectivity.
- NFVi: There are plenty of features that can leverage this flexibly in the NFV realm, as any given Enterprise VNF and Service Provider VNF can run BGP. Imagine running a Wireless LAN Controller and injecting a customer's WLAN prefixes into their MPLS cloud - or even better, their cellular clients.